В прошлом посте я начал говорить про модели. Продолжим с этого же момента.
Если вспомнить определение слова модель , то сразу становиться понятно, что мы будем говорить о некоторой упрощенной сущности. В мире моделей есть понятие формализованной и не формализованной модели. С формализованными моделями все понятно. Берешь готовый инструмент и применяешь, а вот с не формализованными моделями не все так просто. Один из видов не формализованных моделей являются эвристические модели. Казалось бы, о чем это я все и при чем тут какая-то эвристика?
А вот причем. Все модели, которые используются при тест-дизайне относятся к эвристическим моделям. Громкое слово ВСЕ подразумевает под собой всего три базовых модели (на жесткую формулировку не претендую):
• Классы и границы.
• Комбинации классов и границ.
• Состояние переходов.
Сказать, что каждая, из выше перечисленных моделей, является самодостаточной и использование всего одной будет вполне достаточно для «полного» (так я назову условно полное тестирование ПО, которое нас устраивает) тестирования нельзя. В конечном счете нам необходимо будет применить все три модели и не факт что и в данном случае мы перекроемся на все 100%. Но тем не менее применение этих трех моделей в совокупности даст нам наиболее полное представление об исследуемом продукте.
Дальнейшее повествование предлагая разбить на три части ( по числу моделей) и рассмотреть каждую из моделей более детально. Что позволит нам понять область их применения и условия, при которых необходимо это будет сделать.
Классы и границы.
Стоит пару слов сказать еще о том, как надо планировать тесты. Может это не совсем корректное определение того что хочу описать, но не сказать об этом нельзя. При планировании тестов надо определить приоритеты того что будем тестировать. Выше приведенные модели работают как раз на основе этих приоритетов. В первую очередь при тестирование необходимо проверить положительный сценарий, т.е. проверить то что тестируемая функция работает вообще. Если на положительном сценарии тест не проходит, то дальнейшее развитие бессмысленно, ибо пользователю будет недоступен исследуемый функционал. Вторыми по приоритету идут отрицательные сценарии. Отрицательные сценарии и есть предмет исследований с точки зрения тестирования. Поскольку для проверки отрицательных сценариев надо провести столько тестов, сколько существует различных ветвлений в логике программы. Идея данного подхода проста. При положительном сценарии в один тест мы можем сразу поместить все возможные проверки, которые хотели провести и если тест отработает положительно, то мы знаем, что все работает правильно на «положительных» данных и пользователь может получить желаемый результат, если будет вводить правильные данные. Дальше как раз и надо проверят, что же будет с программой, если пользователь будет вводить «отрицательные» данные. Именно тесты направленные на проверку поведения программы при работе с «отрицательными» данными увеличивают общее количество тестов. Я все это веду к тому что все что будет рассказано ниже так или иначе направлено на оптимальную минимизацию тестов, т.е. на их сокращение. Как следует из выше сказанного, сокращать в основном будем как раз тесты, направленные на проверку работы программы с отрицательными данными.
Начнем дальнейшее рассмотрение моделей с «Классов и границ». Рассматривать данную модель надо одновременно с двух понятий. С понятия классов эквивалентности и границ. Почему, спросите вы, сразу с двух понятий? Во первых, рассмотрение классов эквивалентностей целесообразно только тогда когда мы понимаем его границы. Во вторых, рассмотрение границ проводится как раз применительно к классам эквивалентности. Вот такая тавтология.
Что же такое класс эквивалентности. Под классом эквивалентности будем понимать группу предметов (свойств, параметров) обладающих схожими свойствами, что позволяет нам в последствие сделать верным утверждение, что любой представитель класса эквивалентности будет себя вести так же ка и все другие его представители. Я не претендую данным определением на академичность, но смысл данного понятия, как я его понимаю, я постарался передать.
Что касается границ, то тут все просто, границы есть всегда. Я конечно лукавлю, но совсем чуть. Границы возникают там, где можно их измерить, т.е. как только что-то можно измерить исчисляемой характеристикой, то сразу надо говорить о границах этого исчислимого. Исходя из общей теории тестирования, для обеспечения полного тестирования нам необходимо будет перебрать все значения исчисляемого параметра. Надо ли это делать?
Нет. Не надо. Для «полного» тестирования, которое было определено мной выше, нам достаточно проверить границы этого параметра и любое средние значение.
Как же в таких случаях надо проверять границы? В этом случае в первую очередь необходимо определиться, что это за граница. Все границы можно поделить на 2 вида:
1. Односторонние границы.
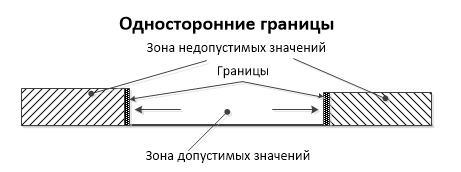
В этом случае у нас нет возможности физически переступить границу и нам необходимо будет проверить поведение нашего продукта, как в самой границе, так и на близких подступах к ней. Для контроля правильности работы основного функционала необходимо брать серединное значение между левой и правой границей. Под «серединным» надо понимать не точно расположенное по середине значение, а любое значение из интервала между границами.
2. Двухсторонние границы.

Подобный вид границ представлен на слайде снизу. Особенность данного вида границ в том что мы потенциально можем перешагнуть через эту границу. В этом случае нам надо строить тесты так что бы была возможность проверить поведение продукта как со значениями вне границ. Со значениями на границе и со значениями приближающимися к границам как со стороны дозволенных параметров, так и со стороне запрещенных параметров.
Исходя из выше сказанного, существует ряд рекомендаций для составления тестов:
1. Серединный тест если выполняется, то значение должно меняться от итерации к итерации.
2. Границы возникают только при наличии числовых характеристик.
3. При тестирование ввода значений необходимо учитывать возможность помещения запрещённых значений в поля ввода нестандартным образом в обход штатного интерфейса.
Рассмотрев существующие виды границ, логично обратиться к их типам.
Существует 4 типа границ:
1. Логическая граница. Определяются здравым смыслом или законами природы. Это границы обусловленные логикой работы самого продукта. Как к примеру масса стола не может быть отрицательной или скидка при продаже не может быть больше и много других подобных примеров.
2. Физические границы. Это такие границы, которые физически нельзя преодолеть. Они похожи на логические, но в отличии от логических границ их нельзя перейти. К примеру, когда нам просят указать длину строки, мы можем спокойно указать отрицательное значение и это мы с вами переходим логическую границу, а когда нас просят ввести строку отрицательной длины, то тут у нас возникает физическая граница, т.к. нет такого способа ввести строку что бы она оказалась отрицательной длины.
3. Произвольные границы. Данный тип границ отличается от всех остальных тем, что они устанавливаются разработчиком в процессе разработке. Часто же возникает ситуация с недостаточной документированностью требований и приходиться предполагать какое значение необходимо использовать как крайне значение. Данный тип границ самый простой и позволяет перемещать эти границы без какого либо болезненного последствия.
4. Технологические границы. Они опасны тем, что они были придуманы или правильнее сказать оговорены стандартами и средствами разработки которые мы с вами используем. Простым примером технологической границы может служит граница типов. Проблема с этими границами состоит в том что как правило ни в документации нет описания их или нет проверок программистов на границы типов и самое страшное в том что при достижении данной границы ее можно перейти и мы попадаем в область не познанного, т.е. нам становиться совсем не понятно что делать с этими данными если у нас к примеру закончились циферки …
Теперь учитывая то, что мы знаем о различных типах границ, у нас есть представления о возможных типах возникающих ошибок.
Ряд рекомендаций, что надо делать или как и где искать.
1. Необходимо организовать такие произвольные ограничения, что бы у пользователя не имелась возможность достижения технологических границ.
2. Уделять особое внимание в местах возможного преобразования типов, что может вести к не эквивалентности пространства вводных данных.
В случае линейности границ можно каждую границу проверять по отдельности и тогда все выше обозначенные рекомендации имеют место, но что делать, когда ограничения взаимосвязаны и образуется некоторая область допустимых значений.
А вышеобозначенныей вариант наиболее часто встречается на практике и именно эти ситуации реально приходиться разбирать.
В данном случае на помощь приходит совокупность подходов применения грниц и классов эквивалентности.
Из теории модельных экспериментов давно известно, если очень много переменных и надо как-то понять как одни переменные влияют на модель в независимости от других, то часть переменных фиксируют и оставляют изменяемыми некоторые из них ( значительно меньше чем это было изначально). В таких сложных ситуациях когда существуют сложные границы, множество различных параметров, для которых границу определить не так легко или невозможно, необходимо как раз провести такое «закрепление» переменных, но фиксировать необходимо не сами значения а четко определять классы эквивалентности среди множества параметров и фиксировать именно классы. Тогда у нас появляется возможность провести желаемое тестирование с минимальными затратами.
Подводя итог под выше сказанным можно дать следующие рекомендации:
1. Для снижения «степеней свободы» при тестирование необходимо фиксировать не сами параметры, а фиксировать утверждения о существующих классах эквивалентности.
2. Планирую серию тестоов тестовые сценарии и тестовые случаи разрабатываются с учетом основного набора параметров (т.е. тех где определены границы и определены взаимосвязи), но при каждом прогоне производить изменения конкретных значений в рамках каждого класса эквивалентности.
На этом с данным постом я закончу.
Очень буду стараться продолжение написать быстрее чем данный пост.
Добрый день. Есть не большая просьба. Пожалуйста, используйте более выраженное форматирование текста, отступы, жирность, пустая строка между абзацами и др. Тяжеловато читать.
ОтветитьУдалитьСпасибо
ОтветитьУдалить